Size and Performance Differences Between Common Python Data Structures
Dec. 21, 2024Over the years, there have been multiple articles and discussions, on which is the python data structure that provides the best performance in terms of memory size, and speed (some examples for this can be seen here and here). Unfortunately, most of the benchmarks use the default options of the data structures, without testing any optimisations.
As I was looking into different data structures to use for a side project of mine, I decided to do some testing and see what are the performance differences between some of the most common data types in 2024, what optimisation options are available, and how the data structures compare with each other when optimisations are applied. This post is the result of the said research.
Experimental Setup
For my side project, I needed a data structure that allows access by key or attribute name. This resulted in me experimenting with the following data types:
- namedtuple
- dictionary
- TypedDict
- dataclass
- pydantic (version 2.9.2)
TypeDict resolves to a regular dictionary, but I like having the option of type hints, so decided to test both structures to see if there is any difference in terms of performance.
For the purpose of the experiment, every data structure holds 25 key-value pairs of data, all of type string, and all tests were done using Python 3.12.7.
Memory usage was calculated for the different data structure instances, and additional instantiation/access time test was performed with the following steps:
# 1) Create a new instance of the data structure.
struct_instance = create_new_struct_instance()
# 2) Access some of the elements of the structure.
access_struct_elements(struct_instance)
After the above steps were completed, the struct instance was explicitly deleted to force garbage collection and clean up the memory for the next iteration of the test. The average time was calculated over 1 000 000 test executions.
The complete source code is available on GitHub.
Basic Structures Test
The first test, which was performed, was on the basic data structures, without any optimisations. The data structures were defined as follows:
BasicNamedTuple = namedtuple(
"BasicNamedTuple",
f"{' '.join([f'key{i}' for i in range(1, 26)])}"
)
BasicDataclass = make_dataclass(
'BasicDataclass',
[(f"key{i}", str) for i in range(1, 26)]
)
fields: dict = {f"key{i}": (str, None) for i in range(1, 26)}
BasicPydanticModel = create_model('BasicPydanticModel', **fields)
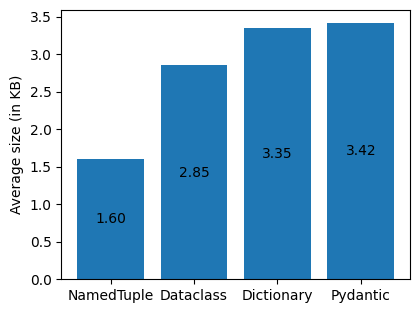
As expected, the average size of the namedtuple instances was the lowest (thanks to the C implementation of the underlying tuple type), followed by the dataclass instances. What is interesting is, that the pydantic model instances were not much bigger on average than the python's built-in dictionary type.
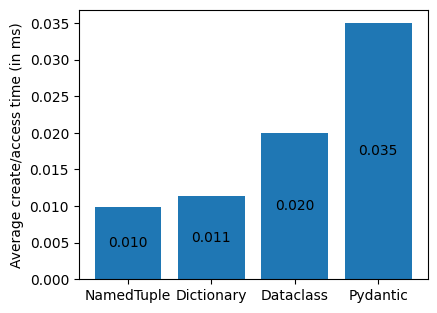
When it comes to the average instantiation and access times, however, the namedtuple and the dictionary type perform much faster than the pydantic model, with the dataclass being somewhat in the middle.
Typed Data Structures
For the second test, I decided to focus on data structures that support type hints, which meant that the basic dictionary and namedtuple were out of the game. Instead, used the TypedDict and NamedTuple classes from the standard library's typing module as replacements for the basic structures.
The definitions of these two new structures were
TypedNamedTuple = NamedTuple(
"TypedNamedTuple", [(f'key{i}', str) for i in range(1, 26)]
)
for the NamedTuple class and
BasicTypedDict = TypedDict(
"BasicTypedDict", {f"key{i}":str for i in range(1, 26)}
)
for the TypedDict.
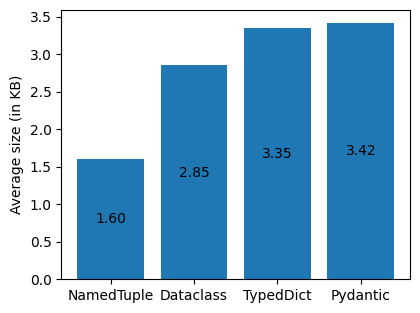
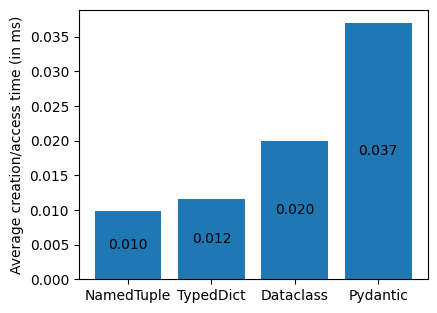
As can be seen, switching to the typing module classes for namedtuple and TypedDict did not change the performance. This is expected, given that TypedDict is essentially a regular dictionary with type hints only recognised by type checkers and ignored by the interpreter, and NamedTuple is calling collections.namedtuple under the hood when creating the data structure instance. This test established the baseline for the overall experiment.
Optimisation Strategies
After setting the baseline for performance testing with the basic structures test above, it was time to see what optimisations are available. NamedTuple and TypedDict are limited to their underlying implementation types, which are tuple and dictionary respectively, so not much can be done in terms of reducing the memory footprint and instantiation and access times.
Therefore, the dataclass and pydantic classes became the targets of performance optimisations.
Dataclass Optimisations
For dataclass optimisations, the test included four different classes:
- the basic dataclass from the baseline test
- a dataclass with
frozen=Trueto create immutable instances. (I didn't expect any actual optimisation to come out of this, but decided to test it anyway)
ImmutableDataclass = make_dataclass(
'ImmutableDataclass',
[(f"key{i}", str) for i in range(1, 26)],
frozen=True
)
- a dataclass with
slots=Trueto create a class without__dict__(this creates a__slots__method under the hood, and is usually used to limit the memory footprint of regular classes)
SlotsDataclass = make_dataclass(
'SlotsDataclass',
[(f"key{i}", str) for i in range(1, 26)],
slots=True,
)
- a dataclass that combines
frozen=Trueandslots=True(this was to see if the instantiation/access time would improve).
OptimisedDataclass = make_dataclass(
'OptimisedDataclass',
[(f"key{i}", str) for i in range(1, 26)],
slots=True,
frozen=True,
)
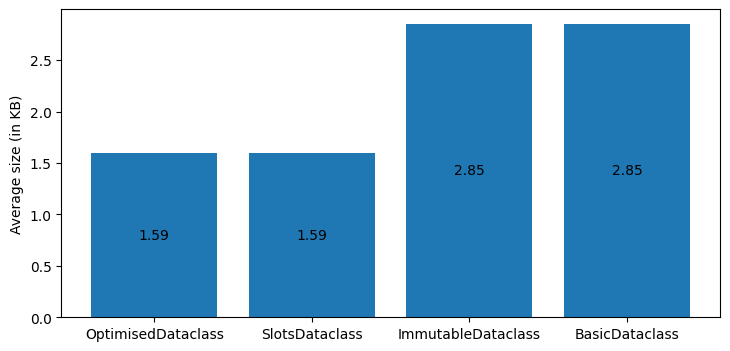
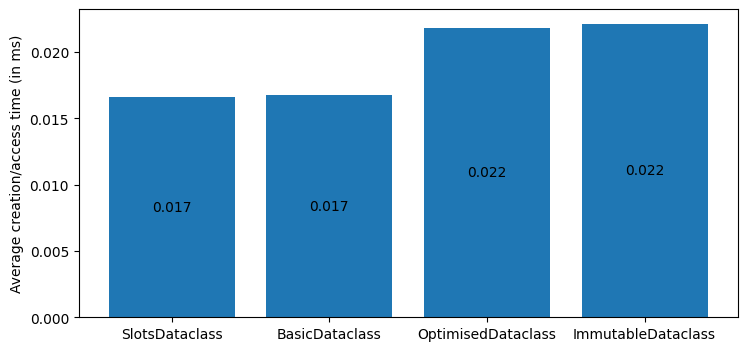
The test showed some interesting results. As expected, the immutable dataclass which used the frozen=True flag had the same memory footprint on average as the basic dataclass. Its average instantiation/access time, however, was greater than the basic dataclass.
On the other hand, the dataclasses that were setting the slots flag used the smallest amount of memory, but the class that was setting both the frozen and slots flags was much slower in terms of instantiation/access time.
At the end, having only the slots flag set, provided the best performance optimisation.
Pydantic Optimisations
After going through the pydantic documentation and more specifically its performance tips guide, it seemed like there were not many things that could be applied to the models that I was using for the performance tests.
I settled for a test model that turns off the caching of strings. It wasn't clear to me whether this would have any effect, given that the test framework which I'm using explicitly deletes every struct instance forcing garbage collection, but as I haven't gone through pydantic's rust implementation, it seemed worth a shot.
CachelessPydanticModel = create_model(
'BasicPydanticModel',
__config__=ConfigDict(cache_strings='none'),
**{f"key{i}": (str, None) for i in range(1, 26)}
)
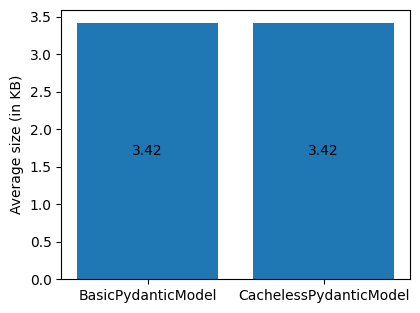
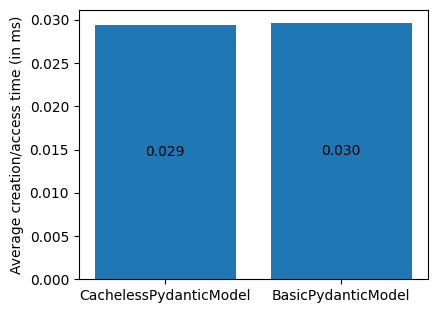
The results from the test, however, showed literally no difference in terms of memory usage and an insignificant difference in instantiation/access times.
Final Test
For the final test, I used the structures from the Typed Data Structures section above, but replaced the basic dataclass with the slots-based dataclass from the Dataclass Optimisation section, and the basic pydantic model was replaced with the cache-less model from the Pydantic Optimisations section.
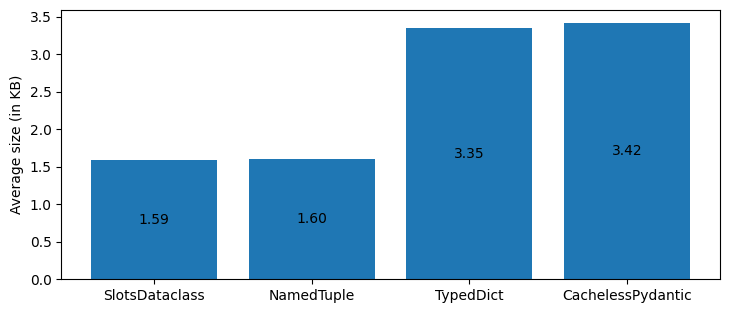
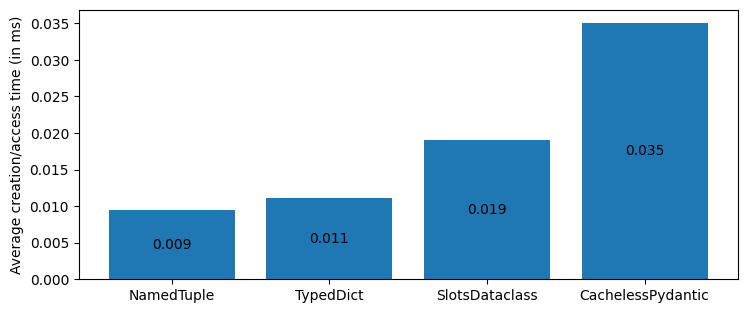
The results show that a dataclass with the "slots" flag set, is actually the most memory efficient data structure, though in terms of instantiation/access time, namedtuples are still much faster thanks to the C implementation of the underlying tuple type.
Conclusion
As of 2024, namedtuples remain the best optimised python data structure in terms of memory usage and speed. Data classes, however, are quite a good alternative and can be optimised to have the same memory footprint as namedtuples. They remain quite slow though in terms of instantiation/access speed. Pydantic models, are incredibly versatile structures with their data validation capabilities, and in version 2 are pretty close in terms of memory usage to the regular python dictionaries (which are probably the most widely used data structure in general). This makes them quite enticing for use cases that don't require high execution speeds.
Hopefully, this article helps you get some insights into the performance of some of the most commonly used data structures in python.
If you have any questions, suggestions or would like to just discuss this post, feel free to email me at curious.bulgarian@proton.me
Last Updated: Dec. 21, 2024, 3:59 p.m.